![[レポート]AWSアナリティクスのイノベーション データウェアハウスと SQL 分析 - Innovations in AWS analytics: Data warehousing and SQL analytics (ANT349)](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート]AWSアナリティクスのイノベーション データウェアハウスと SQL 分析 - Innovations in AWS analytics: Data warehousing and SQL analytics (ANT349)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部のsutoです。
本記事は「AWS re:Invent 2024 - Innovations in AWS analytics: Data warehousing and SQL analytics (ANT349)」のセッションレポートです。
セッションの動画は以下で公開されています。
概要
Join this session to learn about the newest innovations in data warehousing and SQL analytics with AWS analytics services. Amazon Redshift is the AI-powered, cloud-based data warehousing solution used by tens of thousands of AWS customers to modernize data analytics workloads and generate business insights with the best price performance. Learn more about the latest capabilities launched for Amazon Redshift to further drive quick decision-making with lower costs for your organization.
このセッションに参加して、AWS 分析サービスを使用したデータ ウェアハウジングと SQL 分析の最新のイノベーションについて学びましょう。 Amazon Redshift は、AI を活用したクラウドベースのデータウェアハウジング ソリューションで、数万の AWS の顧客がデータ分析ワークロードを最新化し、最高のコストパフォーマンスでビジネスの洞察を生成するために使用しています。組織のコストを削減しながら迅速な意思決定をさらに推進するために、Amazon Redshift 向けにリリースされた最新機能について詳しく説明します。
スピーカー
- Neeraja Rehtachintala (Director of Product Management, Amazon Web Services)
- Rony James (Senior Director of Business Intelligence, Charter Communications)
アジェンダ

セッション内容
Amazon Redshiftの進歩と最近のアップデート
モダンなデータウェアハウジングにおける4つのトレンドとして以下があります。
- Data Lake、データウェアハウス、機械学習のユースケースが融合している
- ニアリアルタイム分析
- データ分析者以外のデータへのアクセスの容易さ
- 堅牢なセキュリティとガバナンスの制御
そのためにAWSは「Amazon Redshift」のイノベーションを続けてきました。
本セッションではAmazon Redshiftの進化と最新機能について解説していました。

Amazon Redshiftのここ12か月の進歩

主だったところとして、
- コストパフォーマンス:TPC-DSで行ったベンチマークの比較で 約3倍 、スループット比較では 約7倍

- ダッシュボードクエリの初回応答時間の向上
- Data Sharingのパフォーマンスも大幅に向上(初回クエリは2023年と比較して146倍高速、データが継続的に更新される場合は最大4倍高速化に)
- Sort KeyやDistribution Keyをより効率的に生成するアルゴリズムも改善
- より小規模な「ra3.large」の登場
- 参考記事:https://dev.classmethod.jp/articles/20241002-amazon-redshift-ra3large/
- これによって、「RedshiftのRA3はまだ高い。もう少しスモールスタートで使えれば」というユーザーにも手を出しやすくなったのが良かった
などの多くのパフォーマンス改善。Redshiftをガッツリ運用している既存ユーザーにとってうれしい改善です。

Redshift Data Sharingについて、ユーザーの使い方としては
- Hub and Spokeモデル:データウェアハウスにデータを集中させ、ダッシュボード、データサイエンスワークロード、アドホッククエリなど、異なる目的のための複数の分析クラスターを持つ
- Data Meshアーキテクチャ:異なるビジネスチームがそれぞれのウェアハウスを維持しながらデータセットで協力する
で展開していることが多い。
これまでのData Sharingは読み取りワークロードの分離のみをサポートしていたが、新たなアップデート「 Multi-warehouse Writes 」によって、ETL処理を含むデータ処理ワークロードのスケーリングが可能になりました。
参考記事:https://dev.classmethod.jp/articles/amazon-redshift-multi-dwh-through-data-sharing-ga/
コンシューマーRedshift(共有される側のRedshift)からデータベースへの書き込みが可能になったということで、よりシームレスにデータ連携でできるようになったのが嬉しいですね。

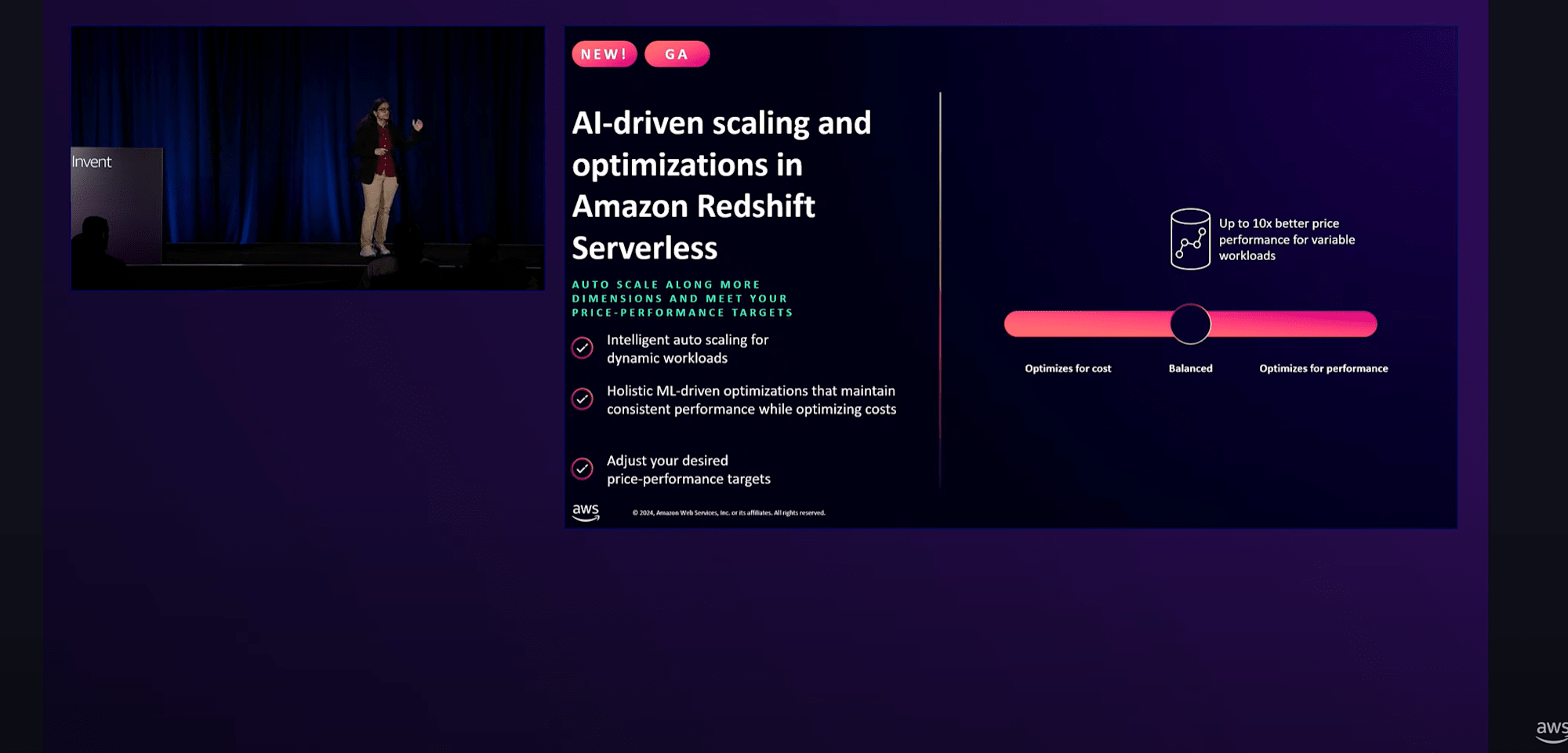
Amazon Redshift Serverlessにおいても、Cross-region Copy、Snapshotスケジューリング、AWS PrivateLinkサポート、最大1024 RPU構成が可能になるなどの他、新たに「 AIドリブンのスケーリングと最適化 」がGAとなりました。
これまでは、同時実行クエリに対するスケーリングによって、コスト効率やスループットを改善できたが、複雑なクエリやデータスキャン量が多いクエリには効果が出ませんでした。
それがAIドリブンのスケーリングと最適化を活用することで、コスト優先 or レスポンス優先かをモード選択することができるようになり、過去のクエリから最適化を測ってくれるように動作できます。
(「お金かけてでもレスポンス早くしてほしい」って要望に応えられるのが良いですね)
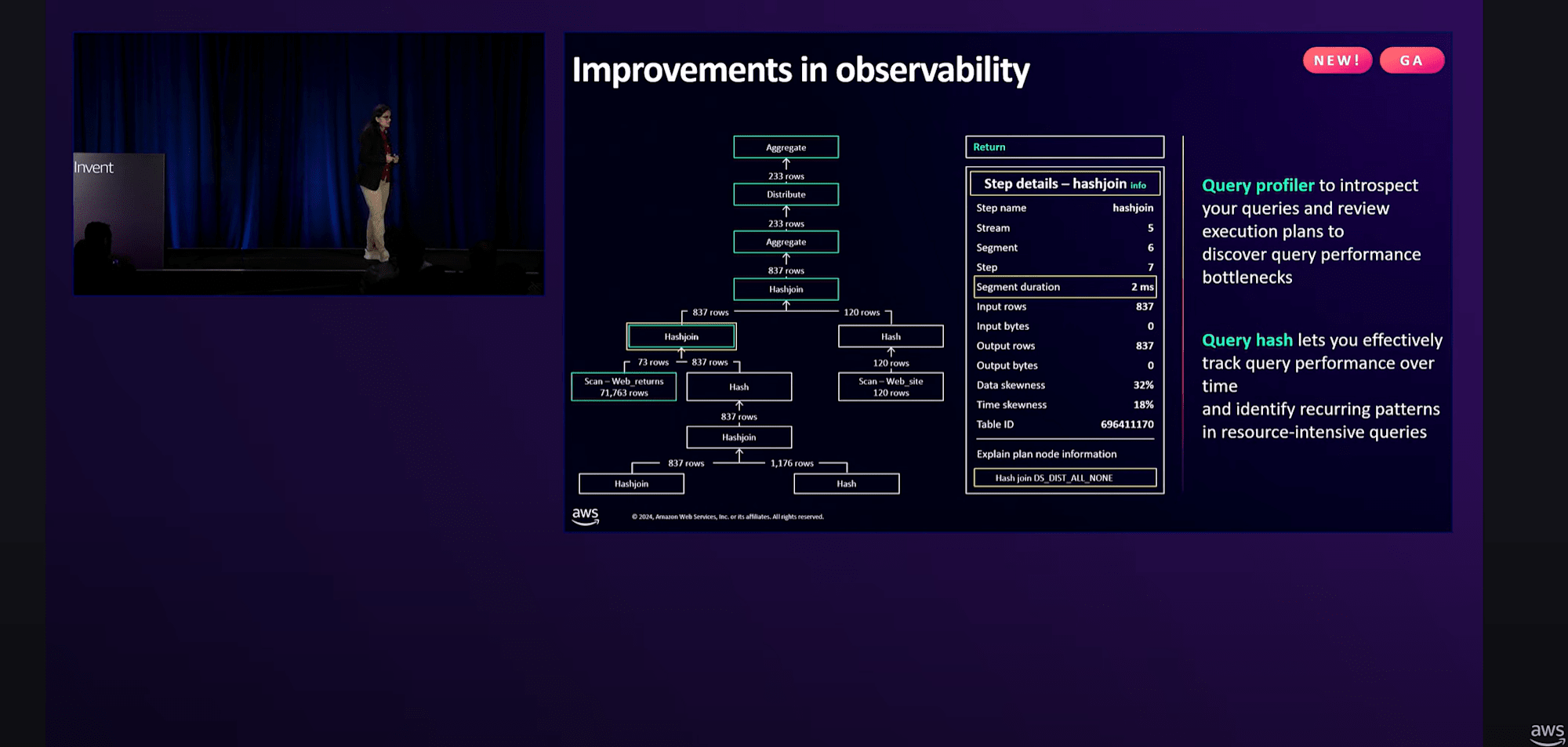
パフォーマンスの改善に加えて、可観測性と使いやすさの面でもいくつかの機能強化を実施
- Query Profiler:クエリ実行プランをグラフィカルに表示し、パフォーマンスの問題を分析およびデバッグすることができる
- Query Hash:SQLクエリの一意の識別子として機能し、特定のクエリのパフォーマンスを時系列で追跡し、繰り返し発生する問題やパターンを特定することができる
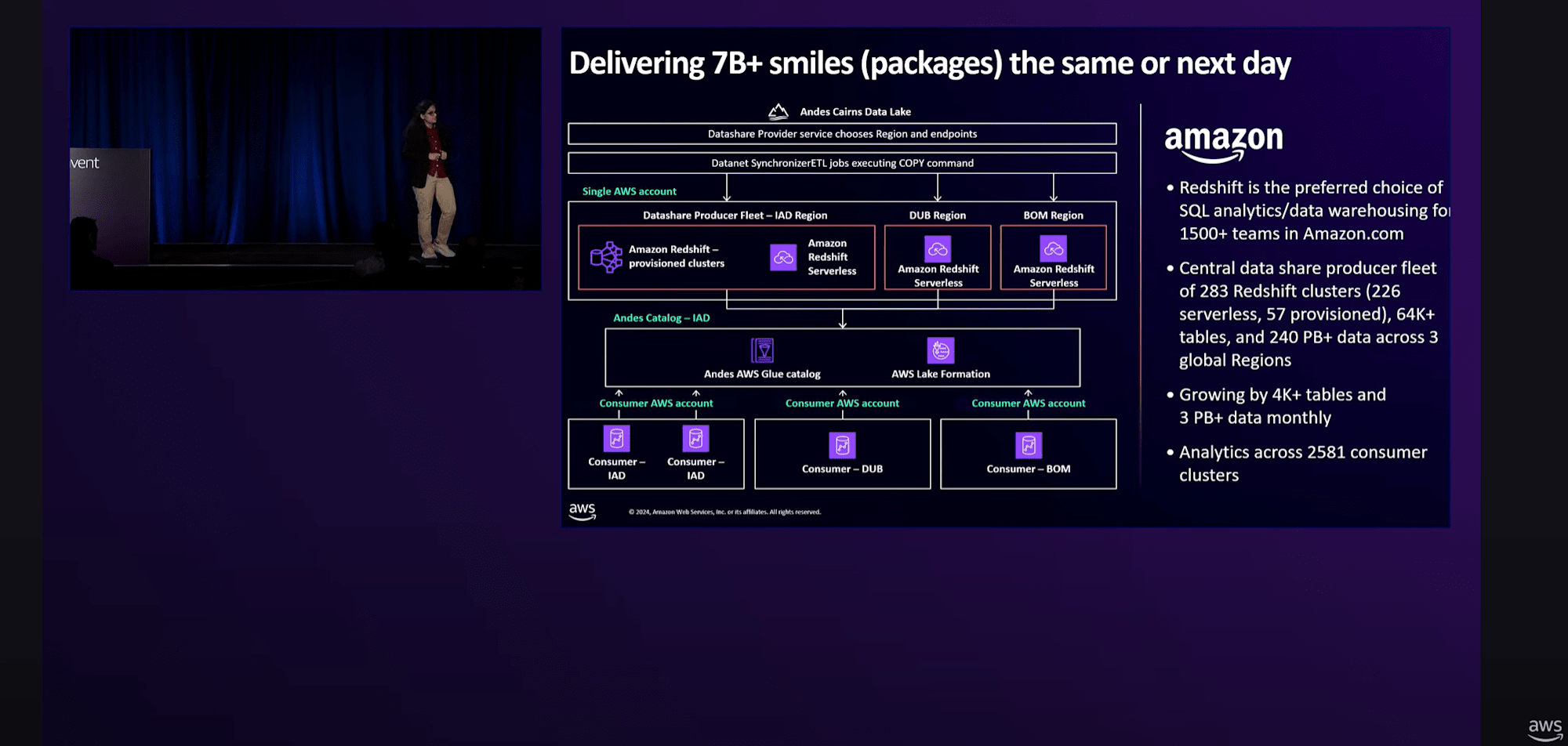
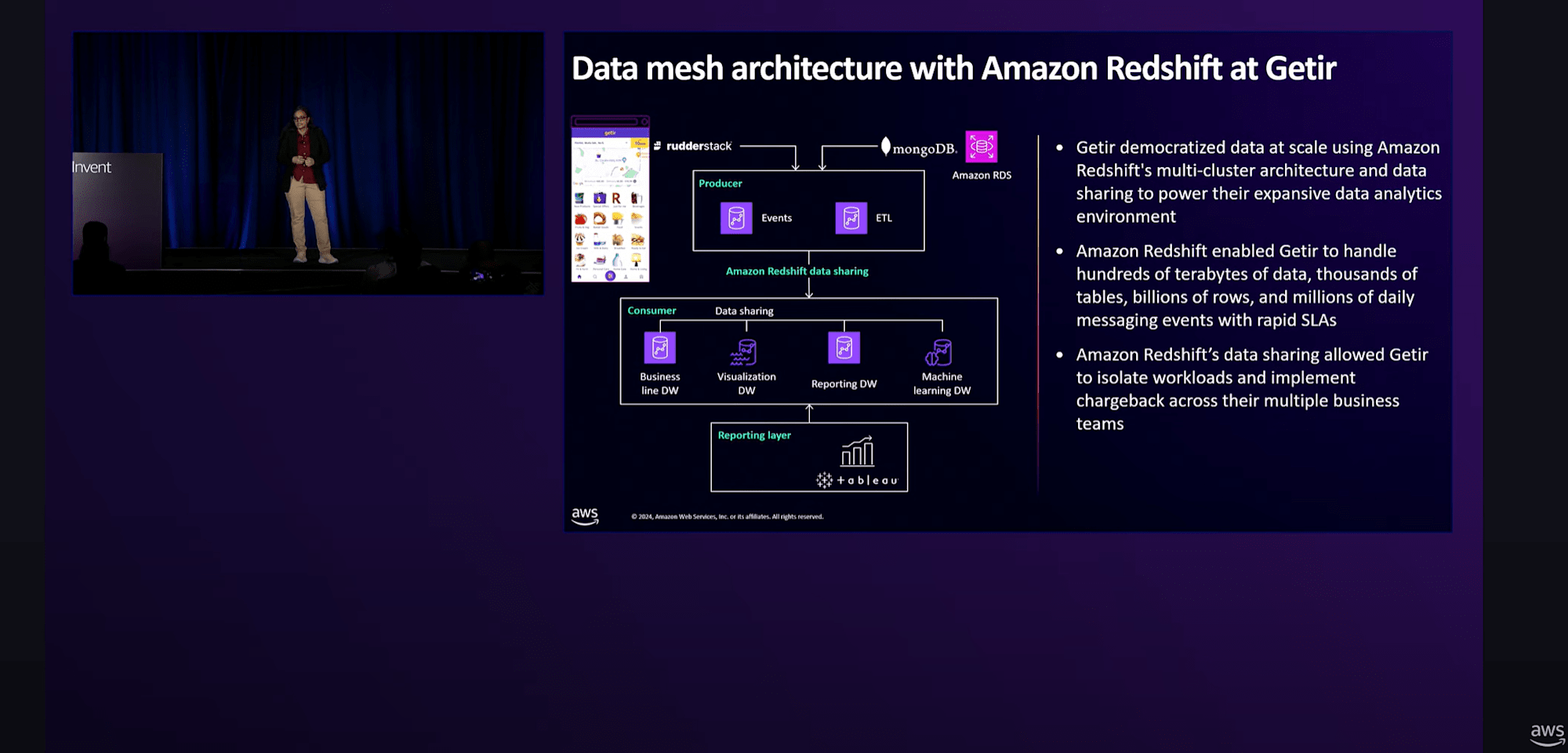
Redshiftの実装事例
Amazon.com
Getir
Criteria

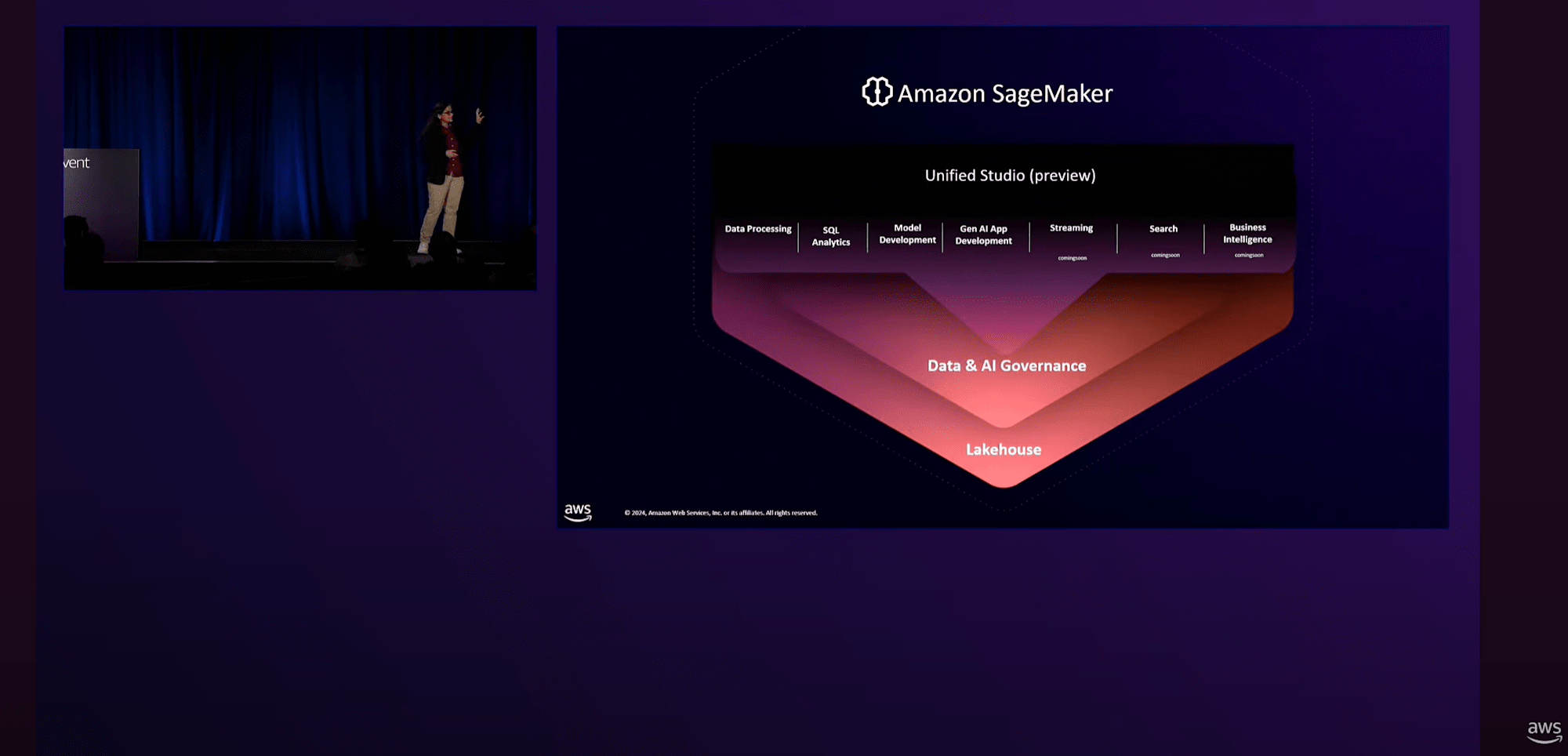
SageMaker Lakehouseとデモンストレーション
SageMaker Lakehouseとは、SageMakerの傘下で、AnalyticsやMachine Learning、AIサービスを1つにまとめたものです。
- S3 Data LakeとRedshift Data Warehouseに存在するデータを統合ビューとして提供
- Iceberg APIを通じて利用可能で、EMRやGlueなどのAWSエンジンや、Icebergと互換性のあるサードパーティのエンジンを使って、Data Warehouseのデータを含むすべてのデータにアクセスできる
- きめ細かいセキュリティ制御が統合されており、すべてのデータに対して一貫した権限設定を適用できる
Trusted Identity Propagationを使用すると、例えばAmazon QuickSightからシングルサインオンを使用して、Redshift、Lake Formation、そしてS3まで、スタック全体を再ログインすることなく通過できます。
そのアップデートとして、
- 各種ドライバーサポート
- AWS IAM Identity CenterとAmazon S3 Access Grantsの統合
など、多くの機能強化を行っています。

RedshiftのメタデータをLakehouseに公開するだけで、Redshiftでマルチウェアハウスアーキテクチャを設定する方法を簡素化

また、Lake HouseでApache Iceberg形式のデータにクエリを実行する際、Redshiftを強力なSQLエンジンとして活用することができるので、パフォーマンスを最大3倍向上できるとのこと。

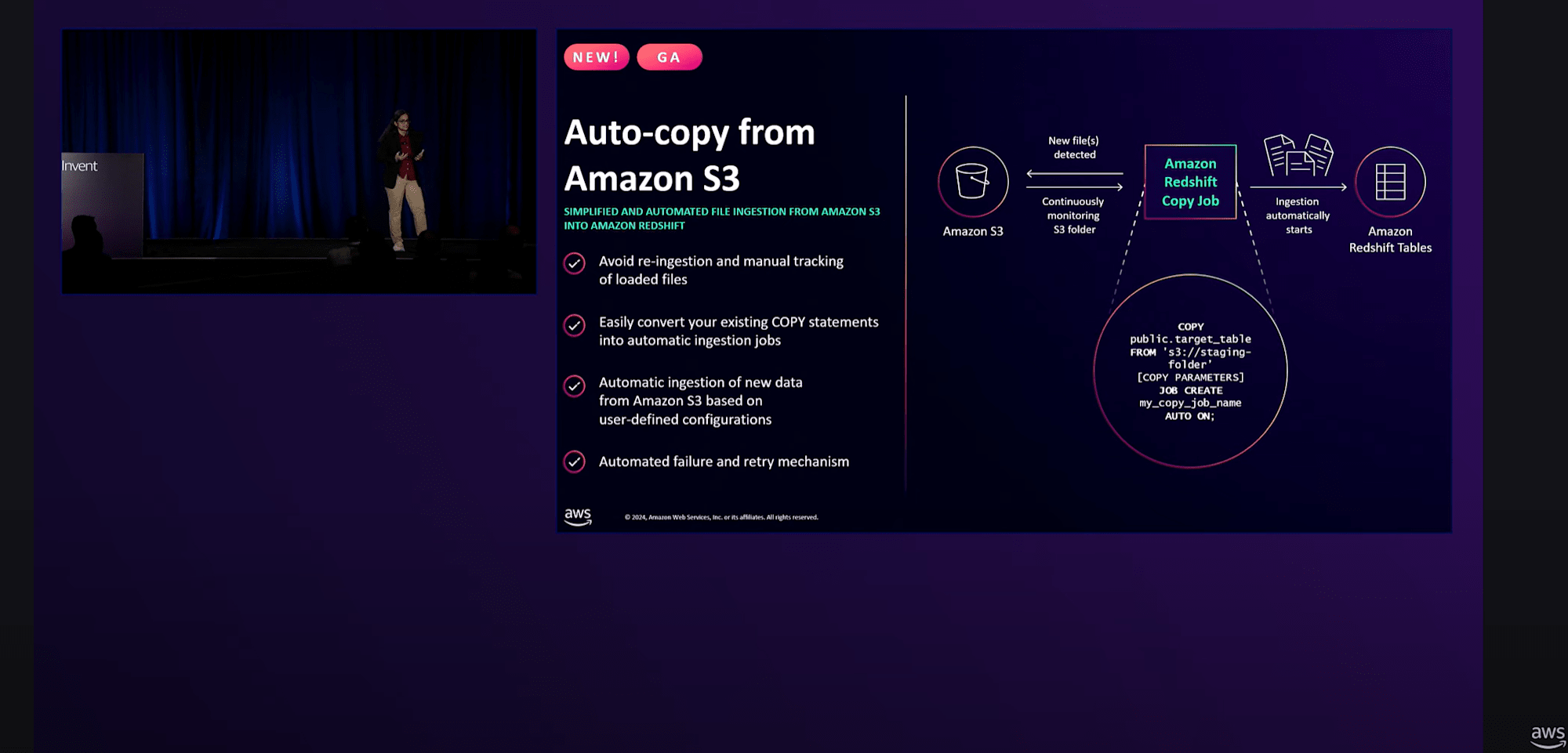
S3からRedshiftへのAuto-copyの機能がGAになっています。これを活用すれば、コピーコマンドの設定やスケジューリング、取り込み済みファイルの追跡について心配する必要がなくなります。
Redshiftへのストリーミング取込機能においても、Confluent CloudやセルフマネージドのApache Kafkaクラスターもサポートされるようになりました。

Streaming ingestionもそうですが、データ取込には「取込方法の簡素化」と「多様なデータソースやアプロケーションへの対応」が求められています。そこで「Zero-ETL」の機能が活きてきます。
Zero-ETLの機能紹介については、私がセッションブログを書いた以下の別のセッションでも詳しく解説していました。
参考記事:https://dev.classmethod.jp/articles/awsreinvent2024-ant330/
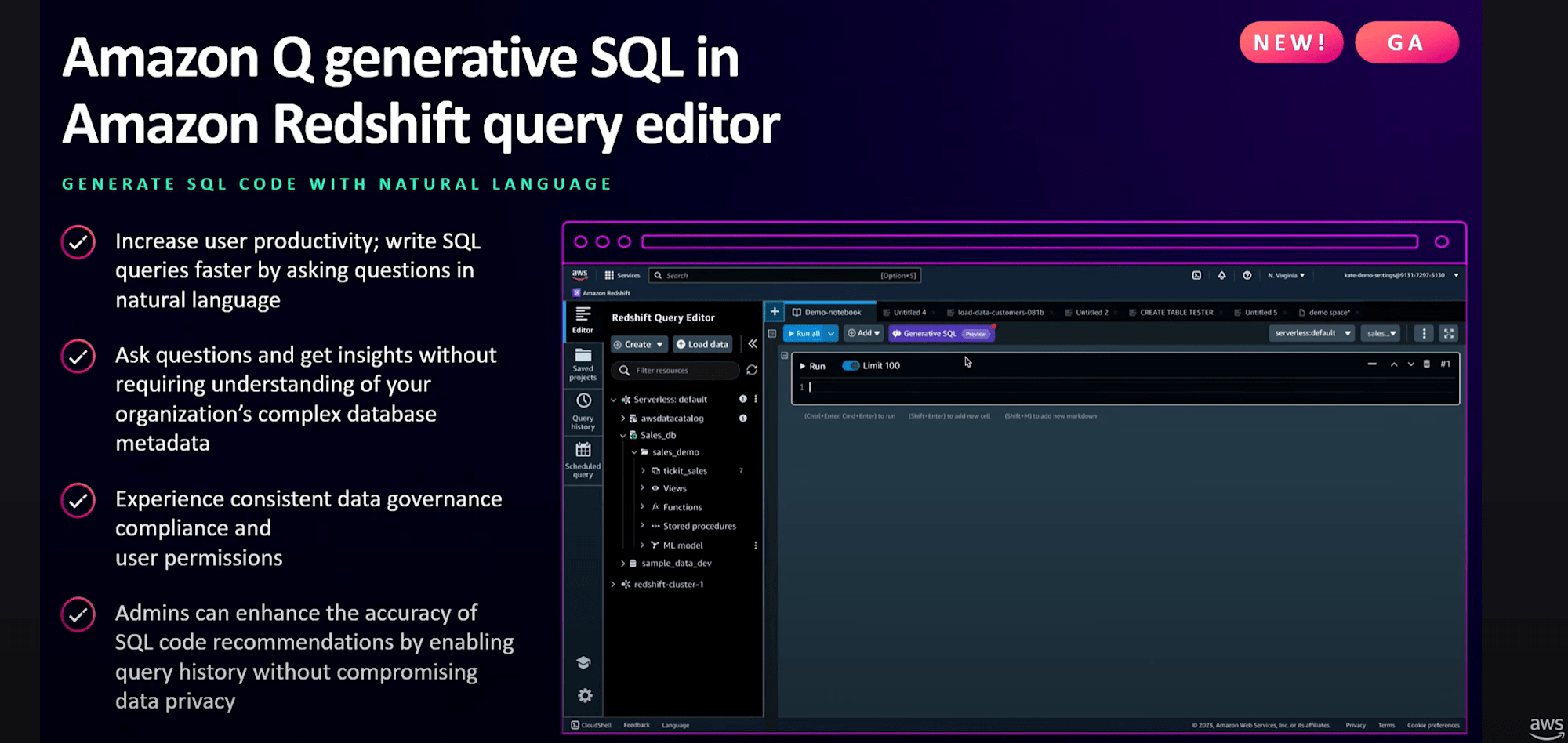
Amazon Redshift Query EditorのGenerative SQL機能が一般提供開始となりました。
参考記事:https://dev.classmethod.jp/articles/20241007-amazon-q-generative-sql-amazon-redshift/
Google Cloudの「 BigQuery データ キャンバス 」と同等の機能かなー。
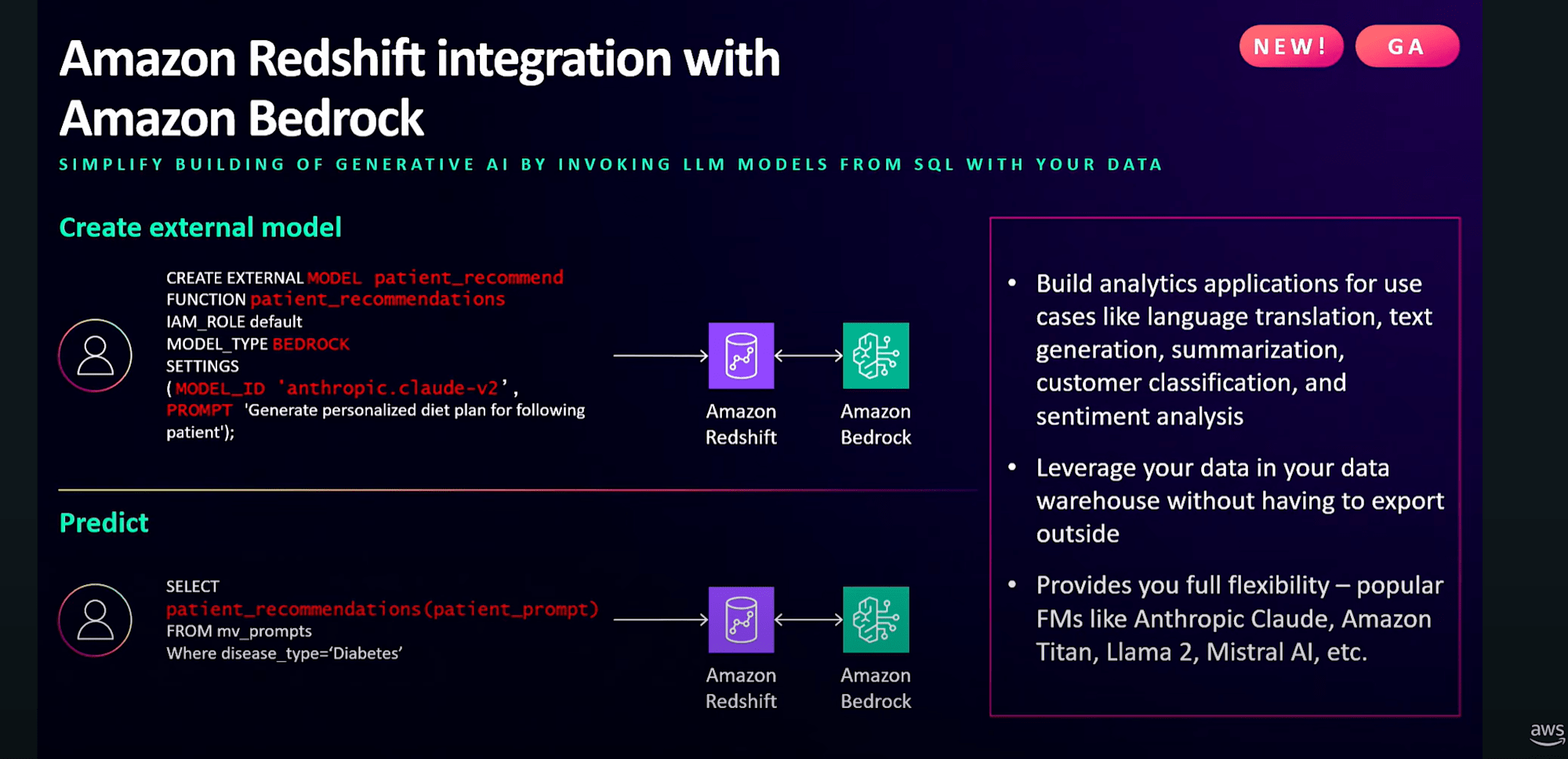
Amazon RedshiftとAmazon Bedrockの統合により、AnthropicのClaude、Amazon Titan、MetaのLlama 2、Mistral AIなどの人気のある基盤モデル(FM)を参照する外部モデルをRedshiftで簡単に作成し、推論のためにSQLの一部として呼び出すことができます。
よってRedshiftデータに対しても言語翻訳、テキスト要約、テキスト生成、顧客分類、感情分析などの生成AIタスクを実行できるようになったので、プロンプトの入力から自身の欲する結果を呼び出せるということで、生成AIによる分析手法がどんどん入ってきているのを実感します。
以降はRedshiftのデータをLake Houseに設定するデモを行っていました。
流れとしては、
- Zero-ETL統合を使用してAmazon RedshiftデータウェアハウスにAurora PostgreSQL、DynamoDB、Salesforceのデータを投入
- ラグは10秒以内という感じ
- Unified Studio の SQL クエリエディタを使用して、SQL クエリの実行
- Jupyter Notebookを開いて、取り込んだ2つのAmazon Redshiftデータウェアハウスにまたがって、未払い残高のある顧客に関するクエリを実行
- Apache Sparkからアクセスできる状態なので、Apache Icebergとの互換性を実演している
- Amazon Bedrockとの連携による感情分析の実行方法を紹介
となっています。
実際の様子はこちらのリンクから。(27:58~36:34あたりまで)
Redshiftへの移行(Charter Communicationsの事例)
ビジネスインテリジェンスチームは、
- 日々、200以上のソースシステムからデータを収集し、50万件以上のクエリを実行して、中央データプラットフォームでデータを整理している
- 中央データプラットフォームを利用する5,000以上のレポートが、様々なビジネスグループに実用的な洞察を提供。店舗、コールセンター、現場レベルのスタッフから、その上司まで、25,000人のビジネスユーザーがこれらのレポーティング製品を利用している
- 有分析プラットフォームを通じて、様々な事業部門から1,000人以上の直接データベースユーザーが部門の分析を行っている

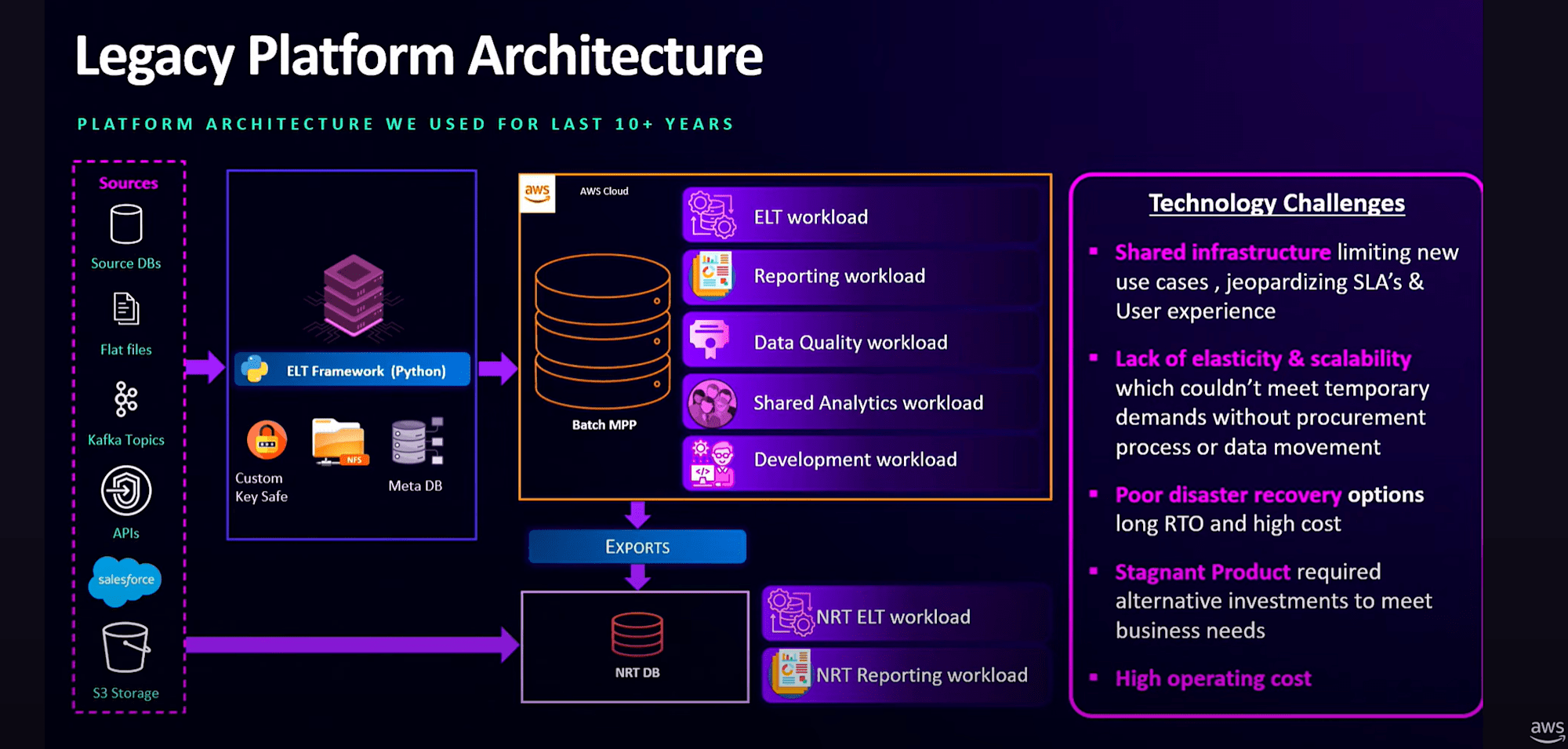
従来システムの課題は、
- バッチ処理の遅延が発生すると、共有分析、部門別のユースケース、レポーティングユーザーの利用を制限せざるを得ない状態
- データ品質ジョブはSLAの完了を待つ必要があり、データの整合性に対する先手を打った対応が難しい状況
- スケーラビリティの柔軟性を高めたい
- RTOとRPOに数週間を要する不十分なディザスタリカバリ
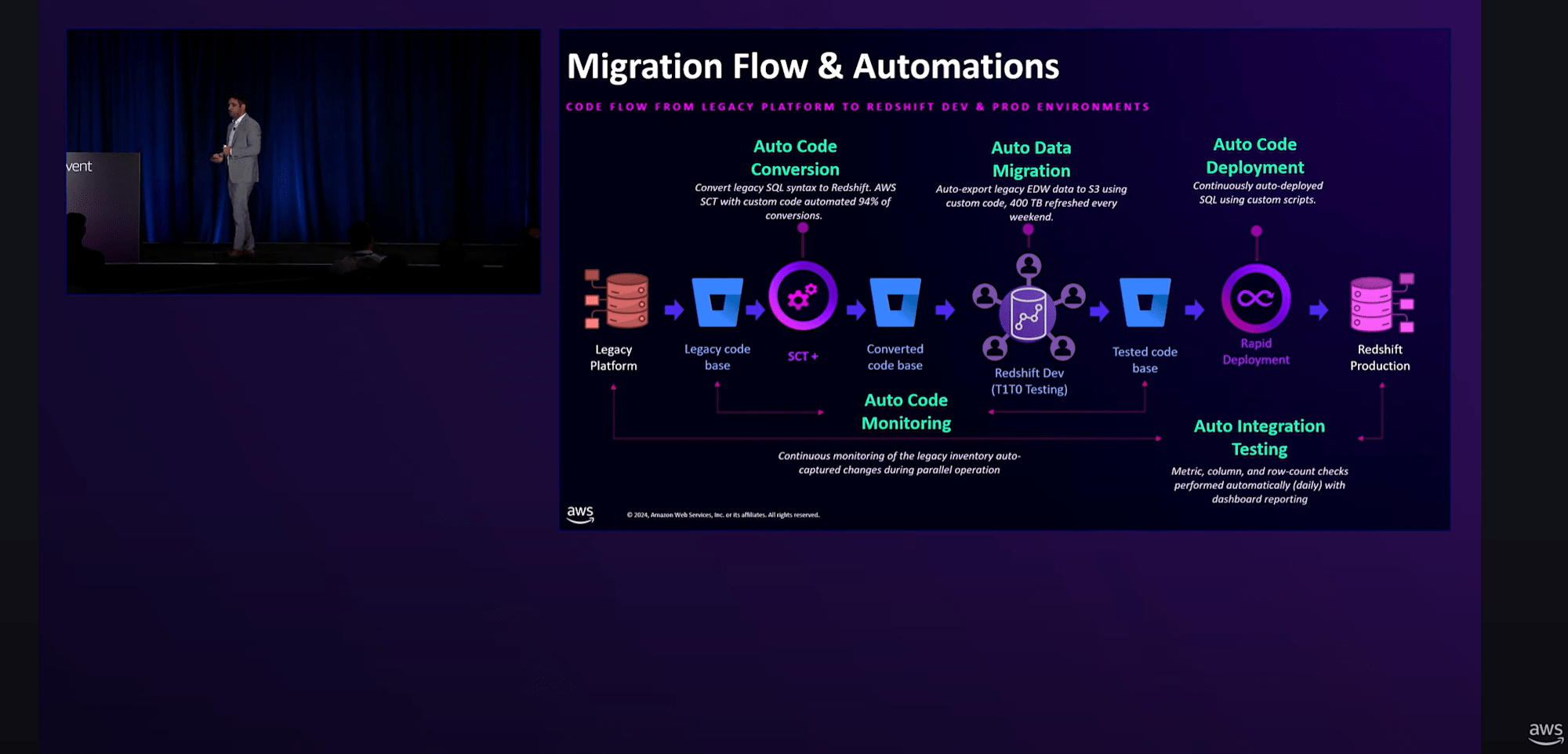
Redshiftへの移行の際には、
- Redshiftチームと協力して、管理者からアナリストまでの各役割に応じたトレーニングプログラムを構築
- AWS Schema Conversion Tool (SCT)の拡張版を活用
- 開発環境でテストされた変換済みコードを本番環境に継続的にデプロイする自動コードデプロイメントを実装
などで移行を加速できた。
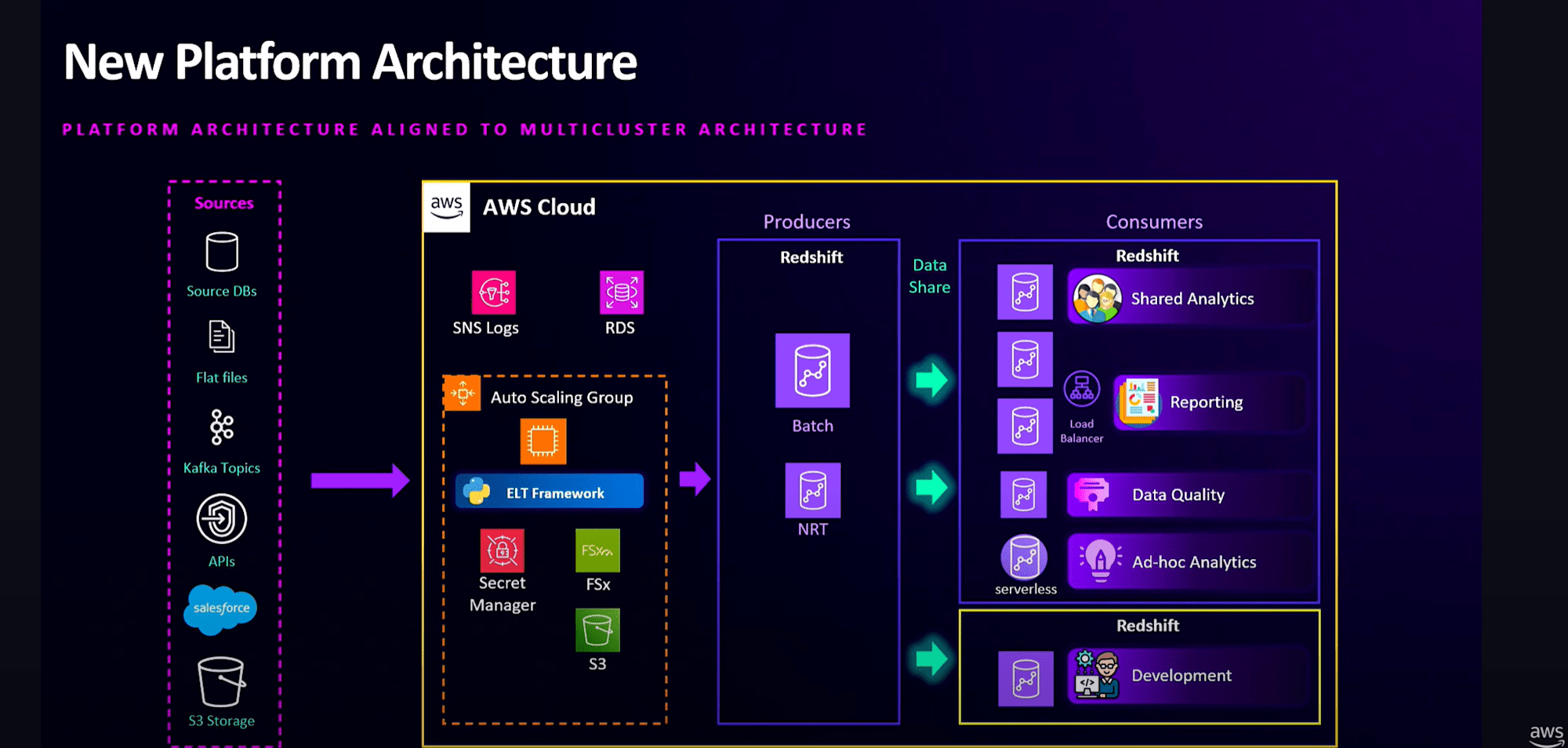
結果、新しいアーキテクチャでは、
- Amazon Redshiftのマルチクラスターアーキテクチャで設計
- ロギングやキー管理においてAWSサービスとの連携を強化
- Producerクラスターとコンシューマクラスターに分かれているので、。バッチ処理中に遅延が発生しても、レポーティングユーザーは作業を中断する必要がない
- データ品質チェックは、データの整合性検証を先回りして行うため、バッチ処理と並行して継続的に実行できる
- 新しいユースケースの導入も非常に迅速に行えるようになった
- 例えば、Amazon Redshift Serverlessを導入してデータ共有を開始したところ、24時間以内にプラットフォームの利用を開始することができた
- ワークロードの分離により、SLA製品で18%の改善
- 災害復旧は現在、RPOが24時間未満、RTOが8時間
- 運用コストを35%削減できた
本セッションのまとめ

最後に
Redshift Data Sharingに関する最新機能と活用事例、マイグレーション事例の内容が充実しているセッションでした。
さらにSageMaker LakehouseやBedrockとの連携のアップデートから「データの取込~ETL~分析~AI活用」が一貫して開発するための統合環境の整備を着々と進めている雰囲気が伝わってきました。










